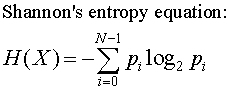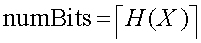Spectral graph theory has a long history. In the early days, matrix theory and linear algebra were used to analyze adjacency matrices of graphs. Algebraic methods have proven to be especially effective in treating graphs which are regular and symmetric. Sometimes, certain eigenvalues have been referred to as the algebraic connectivity" of a graph.
The roots of the characteristic polynomial of a matrix is called the eigenvalues of the matrix. The characteristic polynomial χ of matrix A is defined by, χ(x; A) = det(A − xI). A matrix whose rows form an orthogonal basis of an eigenspace of a graph's adjacency matrix has columns that serve as coordinate vectors of an harmonious geometric realization of the graph. By "harmonious" I mean automorphisms of the graph induce rigid isometries the realization.
"The eigenvalues of a graph are defined as the eigenvalues of its adjacency matrix. The set of eigenvalues of a graph is called a graph spectrum." [WolframAlpha]. Spectral Graph Theory has traditionally used the spectra of specific matrices associated with the graph, such as the adjacency matrix, the Laplacian matrix, or their normalized forms, to provide information about the graph.
"The eigenvalues of a graph are defined as the eigenvalues of its adjacency matrix. The set of eigenvalues of a graph is called a graph spectrum." [WolframAlpha]. Spectral Graph Theory has traditionally used the spectra of specific matrices associated with the graph, such as the adjacency matrix, the Laplacian matrix, or their normalized forms, to provide information about the graph.
Roughly speaking, half of the main problems of spectral theory lie in deriving bounds on the distributions of eigenvalues. The other half concern the impact and consequences of the eigenvalue bounds as well as their applications. In this section, we start with a few basic facts about eigenvalues. Some simple upper bounds and lower bounds are stated. For example, we will see that the eigenvalues of any graph lie between 0 and 2. The problem of narrowing the range of the eigenvalues for special classes of graphs offers an open-ended challenge. Numerous questions can be asked either in terms of other graph invariant or under further assumptions imposed on the graphs. Some of these will be discussed in subsequent chapters.
- Sum of all eigenvalues is ≤ n. Equality holds if G has no isolated vertices.
- principal eigenvalue is always ≤ n/(n-1). Equality holds for complete graphs only.
- If a graph is not complete the principal eigenvalue is le 1.
- If G is connected, then λ1 > 0. If λi = 0 and λi+1 ≠ 0, then the graph has exactly i+1 connected components.
- For all i ≤ n − 1, we have λi ≤ 2, with λn − 1 = 2 if and only if a connected component of G is bipartite and nontrivial.
- The spectrum of a graph is the union of the spectra of its connected components.
A graph G is called spectrally determined if any graph with the same spectrum is isomorphic to G. Of course, one must identify the matrix (e.g., adjacency, Laplacian, etc.) from which the spectrum is taken. Examples of graphs that are spectrally determined by the adjacency matrix:
- Complete graphs.
- Empty graphs.
- Graphs with one edge.
- Graphs missing only 1 edge.
- Regular graphs of degree 2.
- Regular graphs of degree n − 3, where n is the order of the graph.
Some more interesting facts about the eigenvalue of complex networks are,
- The second smallest eigenvalue of the Laplacian L, λ2, is called the algebraic connectivity of G.
- The diameter of a connected graph G is less than the number of distinct eigenvalues of the adjacency matrix of G.
- Spectral Clustering(Shi-Malik algorithm) is one of the popular method for graph clustering algorithm in which the eigenvector corresponding to 2nd smallest eigenvalue of Laplacian Matrix is used to partition the points into two sets. This is used in image segmentation.
- More over it is observed that the smallest eigenvalue of the adjacency matrix of a random network grows almost linearly with respect to the probability p. Degree sequence and eigenvalue spectrum in a random graph are strongly correlated.
Spectral Graph Theory originally focused on specific matrices, such as the adjacency matrix or the Laplacian matrix, whose entries are determined by the graph, with the goal of obtaining information about the graph from the matrices. In contrast, the Inverse Eigenvalue Problem of a Graph seeks to determine information about the possible spectra of the real symmetric matrices whose pattern of nonzero entries is described by a given graph.
The Laplacian and Adjacency matrix contains lots of information, eigenvalues and eigenvectors one of the many techniques to extract some of those information in structured format. This the beauty of both Matrix(which can efficiently store so much information) and the eigenvalue (which can extract meaning out of it).